
Why the heck Single-Threaded Redis is Lightning fast? Beyond In-Memory Database Label


Did you know that Redis can handle up to 500,000 SET and GET operations per second on a single CPU core? This is due to its efficient in-memory data structures and single-threaded architecture.
Redis is a highly popular open-source database that is widely used as a cache, message broker, and data structure store. One of the most remarkable things about Redis is that it is a single-threaded application that still delivers top-notch performance, processing vast amounts of data in real time with low response times. This article will explore the reasons behind Redis' performance and how it leverages its single-threaded design to achieve optimal performance.
Section 1: How Redis Uses I/O Multiplexing to Achieve Concurrency
I/O multiplexing means monitoring multiple client connections using a single thread, without blocking the thread. I/O multiplexing achieves the almost or apparent concurrency. In a multi-threaded application, each thread is typically associated with a single I/O stream. This means that if an application needs to manage multiple I/O streams, it would require multiple threads, each handling a single I/O stream. However, this approach has several drawbacks, such as increased memory overhead, thread synchronization overhead, and context switching overhead.
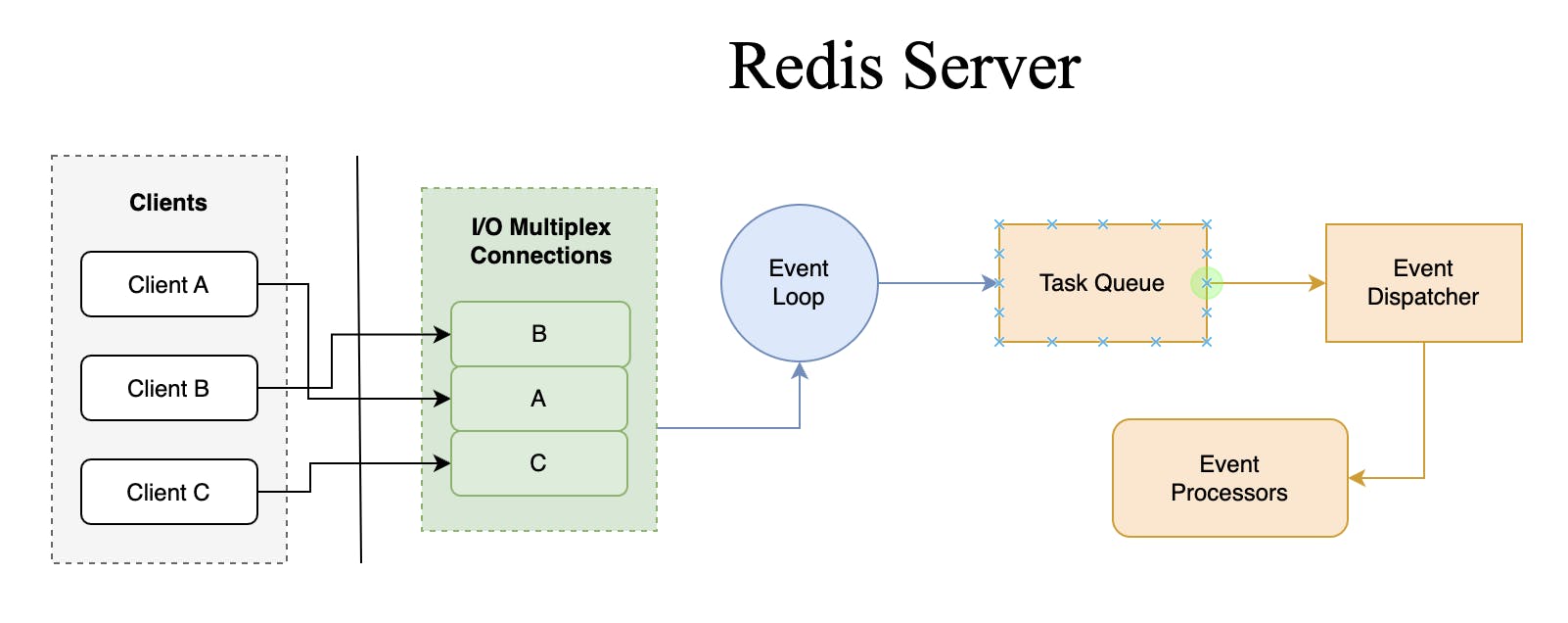
I/O multiplexing solves these problems by allowing a single thread to monitor multiple I/O streams concurrently. This is achieved by using operating system-provided system calls such as select, poll, or epoll, which allow the application to wait for events on multiple I/O streams simultaneously. When an event occurs on one of the I/O streams, the operating system notifies the application, which can then process the event and continue monitoring the other I/O streams. Moreover, I/O multiplexing allows Redis to make optimal use of the underlying hardware resources, such as CPU and network bandwidth.
Section 2: Redis as an In-Memory Database
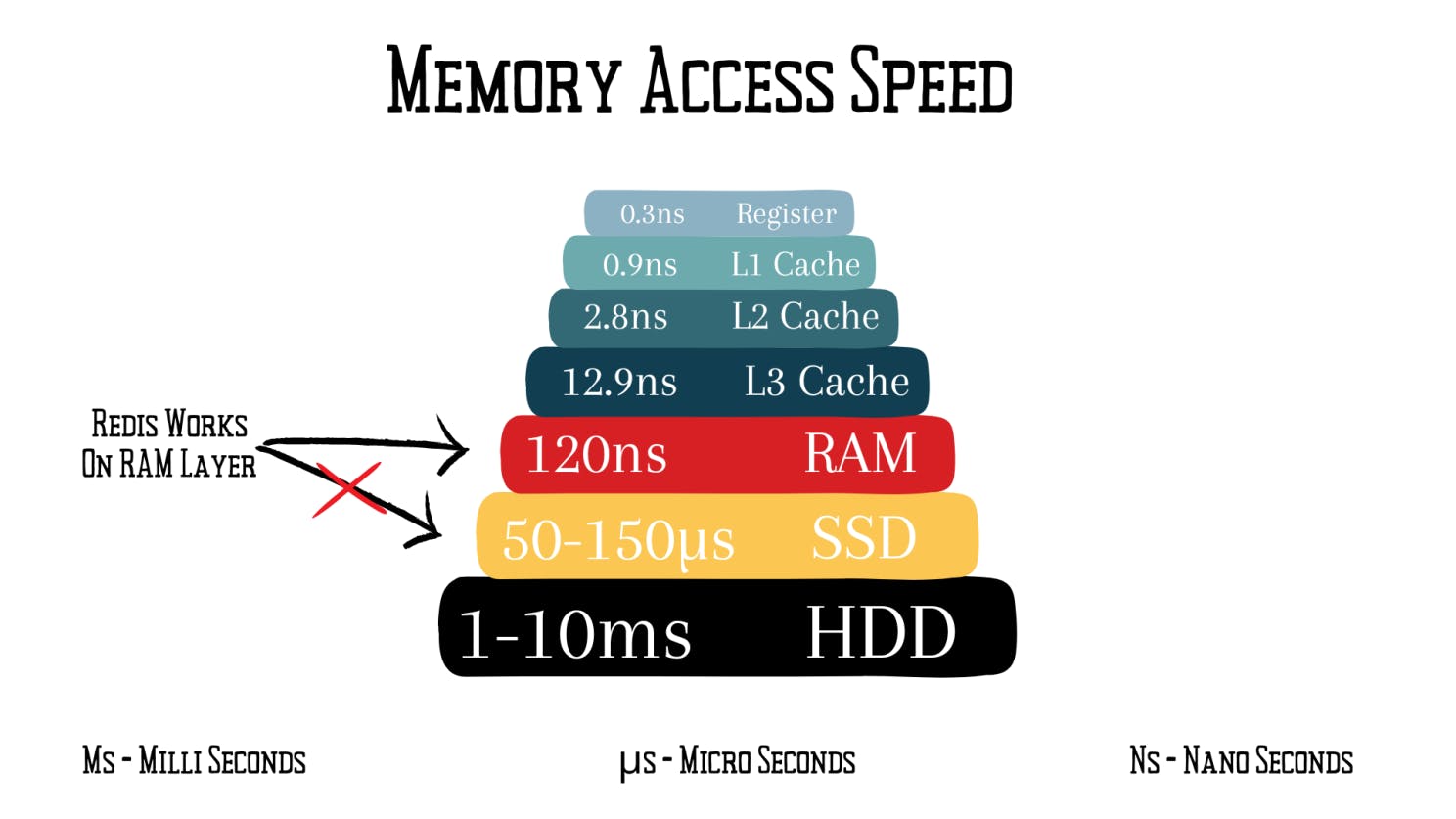
Redis leverages its in-memory architecture to deliver lightning-fast performance compared to disk-based databases. While RAM latency is around 100-120 nanoseconds, SSDs and HDDs have latencies of 50-150 microseconds and 1-10 milliseconds, respectively. By storing all data in RAM, Redis can retrieve and process data much more quickly than traditional disk-based databases.
Section 3: Redis' Atomic Commands and Consistency
Redis' atomic commands guarantee that Redis commands will either execute entirely or not at all. Redis achieves atomicity by using a single-threaded architecture where all commands are executed in sequential order, one at a time. This approach helps Redis maintain consistency and avoid race conditions, even in concurrent and multi-client environments. You can use an example like the INCR command to illustrate how Redis ensures that each command returns the correct result.
Section 4: How Pipelining Improves Performance
Redis uses pipelining to improve performance. Pipelining allows clients to send multiple requests in a single network packet, which Redis processes as a batch, without waiting for a response after each request. This approach reduces network overhead and improves the overall throughput of the system. You can provide an example to explain how pipelining works.
Section 5: Other Optimization Techniques Used by Redis
Redis also uses such as memory allocation optimization, thread-safe data structures, and caching. Redis leverages low-level data structures like Linked List, Skip List, and Hash Table to deliver top-notch performance.
Section 6: Use Cases of Redis Other Than Traditional GET/SET Commands (for the next article)
Redis is one of the most widely used databases but most people don’t use its powers to the full extent. Actually, I’ve seen mostly developers just working on it for get/set commands. Redis is much more than just getting and setting strings for the cache. What makes Redis even faster is due to being an in-memory database it leverages a lot of low-level data structures like Linked List, Skip List, Hash Table and many more. Will explain more in the coming newsletters. Subscribe so you won’t miss the updates.
While Redis' single-threaded architecture offers several advantages, there are also some potential disadvantages to consider. Here are some of the cons of being a single-threaded database:
Limited CPU utilization: A single-threaded architecture means that Redis can only use a single CPU core at a time. This can limit the performance of Redis in multi-core systems, where other databases that support multi-threading may perform better.
Blocking Operations: Redis uses a non-blocking I/O multiplexing technique to avoid blocking the thread on I/O operations. However, some Redis commands, such as blocking commands like BLPOP or BRPOP, can block the entire server until they are complete. This can cause performance issues in certain scenarios.
Memory Usage: Redis stores all its data in memory, which can limit the size of data sets that Redis can handle. As Redis only uses a single thread, it can become challenging to manage large data sets on a single server.
No Built-in Sharding Support: Redis does not have built-in support for sharding, which can make it challenging to scale Redis horizontally. Sharding can help distribute data across multiple nodes, but with a single-threaded architecture, it can become difficult to manage multiple shards effectively.
However, its performance is not limited by its single-threaded design, thanks to its optimized data structures, efficient persistence mechanisms, and event-driven, non-blocking I/O mechanism. Redis is lightweight, scalable, and fault-tolerant, making it an excellent choice for modern distributed systems. Its speed and efficiency have made it a popular choice among developers for caching, session management, and real-time data processing.
Conclusion:
This article explored how Redis leverages its single-threaded design to achieve optimal performance. We discussed how Redis uses I/O multiplexing to achieve the illusion of concurrency, how its atomic commands guarantee consistency, and how pipelining improves performance. We also briefly touched on other optimization techniques used by Redis and hinted at Redis' many use cases beyond the typical GET/SET commands. Despite some potential drawbacks of being a single-threaded database, Redis remains a top-performing database, thanks to its optimized data structures, efficient persistence mechanisms, and event-driven, non-blocking I/O mechanism.
Cheers! 🥂